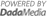Update2026.06.15 (월)

 ▲ 3D 데이터셋 증류 기술 개요(출처: UNIST)
▲ 3D 데이터셋 증류 기술 개요(출처: UNIST)국내 연구진이 사물 인식 인공지능(AI) 모델의 학습 효율을 극대화하는 기술을 개발해 AI 모델 개발에 드는 시간과 연산 비용 개선에 기여할 전망이다.
UNIST는 인공지능대학원 심재영 교수팀이 3D 포인트 클라우드(Point Cloud) 데이터를 효과적으로 압축해 학습 효율을 높이는 ‘데이터 증류(dataset distillation)’ 기술을 개발했다고 1일 밝혔다.
데이터 증류는 대규모 학습 데이터 중 요점만을 추출해 새로운 ‘요약 데이터’를 만들어내는 기술이다. 3D 포인트 클라우드 데이터는 이 데이터 증류 기술 적용이 까다로운 형태의 데이터로 꼽히는데, 사물을 점으로 표현해 놓은 데이터라 점들의 배열에 정해진 순서가 없고, 물체가 회전해 있는 경우가 많은 특성 때문이다.
이러한 특성은 요약 데이터를 생성하는 과정에서 치명적인 걸림돌이 된다. 데이터 증류는 원본 데이터와 요약 데이터의 특징을 비교하는 방식으로 요약 데이터의 완성도를 높여 나가게 되는데, 위와 같은 데이터 특성 때문에 제대로 된 비교가 불가능하다. 때문에 엉뚱한 부위끼리 비교하게 되거나 같은 물체도 다른 물체로 인식해 잘못된 정보가 반영된 요약 데이터를 만들게 된다.
연구팀은 해당 문제를 해결한 데이터 증류 기술을 개발했다. 순서가 제각각인 점 데이터의 의미 구조를 자동으로 정렬해주는 손실 함수(SADM)와 물체의 회전 각도를 AI가 스스로 최적화해 학습하도록 하는 방향 최적화(learnable rotation) 기법이 적용된 기술이다.
개발된 데이터 증류 기술은 원본 대비 수십 분의 1 수준으로 데이터를 줄여도 모델 정확도를 유지하는 것으로 확인됐다.
특히 특정 데이터셋(ModelNet40)에서는 데이터를 원본 크기의 25분의 1로 줄인 요약 데이터로 학습해도 80.1퍼센트의 인식 정확도를 기록해, 전체 데이터로 학습했을 때의 87.8퍼센트와 큰 차이가 나지 않았다. 이는 높은 압축률에서도 학습 효율과 성능을 균형 있게 확보할 수 있음을 보여주는 결과라는 설명이다.
심재영 교수는 “이번 기술은 3D 점 데이터의 무질서한 구조와 회전 불확실성으로 인해 기존 기술들이 겪던 매칭 오류를 근본적으로 해결한 것”이라며, “자율주행, 드론, 로봇, 디지털 트윈 등 대규모 3D 데이터 활용이 필요한 분야에서 AI 학습 비용과 시간을 크게 줄이는 데 기여할 수 있을 것”이라고 말했다.